> ## Documentation Index
> Fetch the complete documentation index at: https://wb-21fd5541-dependabot-github-actions-actions-cache-6.mintlify.site/llms.txt
> Use this file to discover all available pages before exploring further.
# Scikit-Learn
> Utilisez W&B pour visualiser et comparer les performances des modèles scikit-learn grâce au suivi des expériences et à l’enregistrement automatique des graphiques.
Vous pouvez utiliser wandb pour visualiser et comparer les performances de vos modèles scikit-learn en quelques lignes de code seulement. [Essayez un exemple →](https://wandb.me/scikit-colab)
## Bien démarrer
### Inscrivez-vous et créez une clé API
Une clé API permet d’authentifier votre machine auprès de W\&B. Vous pouvez générer une clé API à partir de votre profil utilisateur.
Pour une méthode plus directe, accédez aux [Paramètres utilisateur](https://wandb.ai/settings) et créez une clé API. Copiez immédiatement la clé API et conservez-la dans un endroit sûr, par exemple dans un gestionnaire de mots de passe.
1. Cliquez sur l’icône de votre profil utilisateur dans le coin supérieur droit.
2. Sélectionnez **Paramètres utilisateur**, puis faites défiler jusqu’à la section **API Keys**.
### Installer la bibliothèque `wandb` et se connecter
Pour installer la bibliothèque `wandb` localement et vous connecter :
1. Définissez la [variable d'environnement](/fr/models/track/environment-variables/) `WANDB_API_KEY` avec votre clé API.
```bash theme={null}
export WANDB_API_KEY=
```
2. Installez la bibliothèque `wandb` et connectez-vous.
```shell theme={null}
pip install wandb
wandb login
```
```bash theme={null}
pip install wandb
```
```python theme={null}
import wandb
wandb.login()
```
```notebook theme={null}
!pip install wandb
import wandb
wandb.login()
```
### Consigner des métriques
```python theme={null}
import wandb
wandb.init(project="visualize-sklearn") as run:
y_pred = clf.predict(X_test)
accuracy = sklearn.metrics.accuracy_score(y_true, y_pred)
# Pour enregistrer des métriques au fil du temps, utilisez run.log
run.log({"accuracy": accuracy})
# OU pour enregistrer une métrique finale à la fin de l'entraînement, vous pouvez aussi utiliser run.summary
run.summary["accuracy"] = accuracy
```
### Créer des graphiques
#### Étape 1 : Importez wandb et initialisez un nouveau run
```python theme={null}
import wandb
run = wandb.init(project="visualize-sklearn")
```
#### Étape 2 : Visualiser les graphiques
#### Graphiques individuels
Après avoir entraîné un modèle et effectué des prédictions, vous pouvez générer des graphiques dans wandb pour analyser ces prédictions. Voir la section **Graphiques pris en charge** ci-dessous pour obtenir la liste complète des graphiques pris en charge.
```python theme={null}
# Visualiser un graphique unique
wandb.sklearn.plot_confusion_matrix(y_true, y_pred, labels)
```
#### Tous les graphiques
W\&B propose des fonctions comme `plot_classifier`, qui génèrent plusieurs graphiques pertinents :
```python theme={null}
# Visualiser tous les graphiques de classification
wandb.sklearn.plot_classifier(
clf,
X_train,
X_test,
y_train,
y_test,
y_pred,
y_probas,
labels,
model_name="SVC",
feature_names=None,
)
# Tous les graphiques de régression
wandb.sklearn.plot_regressor(reg, X_train, X_test, y_train, y_test, model_name="Ridge")
# Tous les graphiques de clustering
wandb.sklearn.plot_clusterer(
kmeans, X_train, cluster_labels, labels=None, model_name="KMeans"
)
run.finish()
```
#### Graphiques Matplotlib existants
Les graphiques créés avec Matplotlib peuvent également être enregistrés sur le tableau de bord W\&B. Pour cela, vous devez d'abord installer `plotly`.
```bash theme={null}
pip install plotly
```
Enfin, vous pouvez enregistrer les graphiques dans le tableau de bord de W\&B comme suit :
```python theme={null}
import matplotlib.pyplot as plt
import wandb
with wandb.init(project="visualize-sklearn") as run:
# effectuez tous les plt.plot(), plt.scatter(), etc. ici.
# ...
# au lieu d'appeler plt.show(), faites :
run.log({"plot": plt})
```
## Graphiques pris en charge
### Courbe d'apprentissage
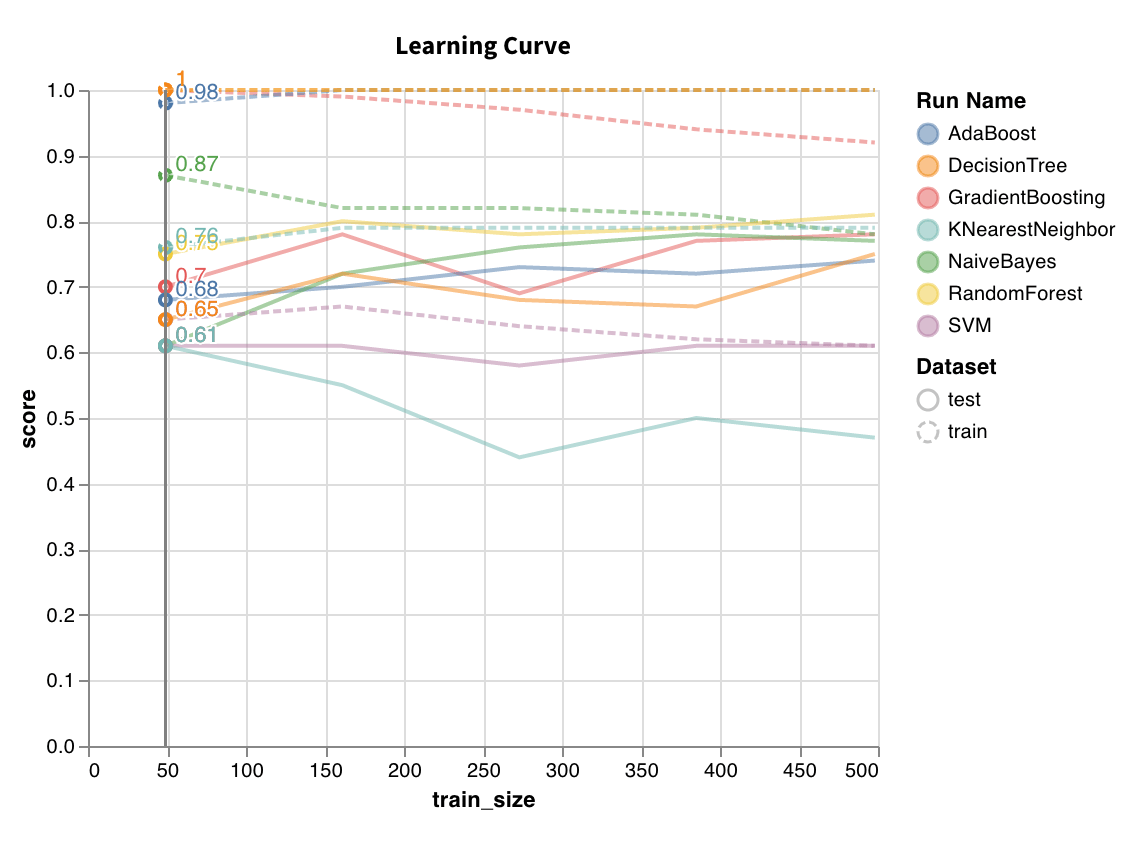 Entraîne un modèle sur des jeux de données de tailles variables et génère un graphique des scores de validation croisée en fonction de la taille du jeu de données, pour les ensembles d'entraînement et de test.
`wandb.sklearn.plot_learning_curve(model, X, y)`
* model (clf or reg): Prend en entrée un régressseur ou un classifieur ajusté.
* X (arr): Fonctionnalités du jeu de données.
* y (arr): Étiquettes du jeu de données.
Entraîne un modèle sur des jeux de données de tailles variables et génère un graphique des scores de validation croisée en fonction de la taille du jeu de données, pour les ensembles d'entraînement et de test.
`wandb.sklearn.plot_learning_curve(model, X, y)`
* model (clf or reg): Prend en entrée un régressseur ou un classifieur ajusté.
* X (arr): Fonctionnalités du jeu de données.
* y (arr): Étiquettes du jeu de données.
### ROC
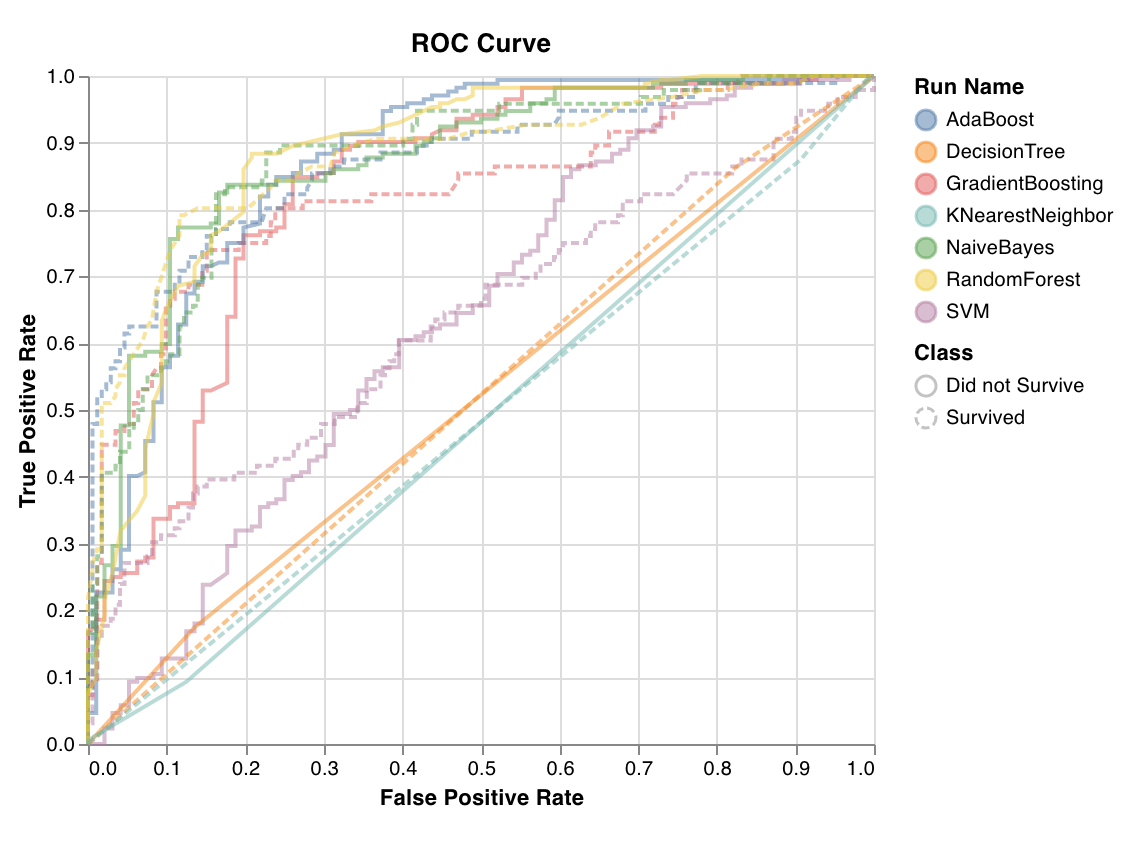 Les courbes ROC représentent le taux de vrais positifs (axe y) par rapport au taux de faux positifs (axe x). Le score idéal est un TPR = 1 et un FPR = 0, ce qui correspond au point situé en haut à gauche. En général, on calcule l’aire sous la courbe ROC (AUC-ROC), et plus l’AUC-ROC est élevée, mieux c’est.
`wandb.sklearn.plot_roc(y_true, y_probas, labels)`
* y\_true (arr): Étiquettes de l’ensemble de test.
* y\_probas (arr): Probabilités prédites pour l’ensemble de test.
* labels (list): Libellés des classes pour la variable cible (y).
Les courbes ROC représentent le taux de vrais positifs (axe y) par rapport au taux de faux positifs (axe x). Le score idéal est un TPR = 1 et un FPR = 0, ce qui correspond au point situé en haut à gauche. En général, on calcule l’aire sous la courbe ROC (AUC-ROC), et plus l’AUC-ROC est élevée, mieux c’est.
`wandb.sklearn.plot_roc(y_true, y_probas, labels)`
* y\_true (arr): Étiquettes de l’ensemble de test.
* y\_probas (arr): Probabilités prédites pour l’ensemble de test.
* labels (list): Libellés des classes pour la variable cible (y).
### Proportions des classes
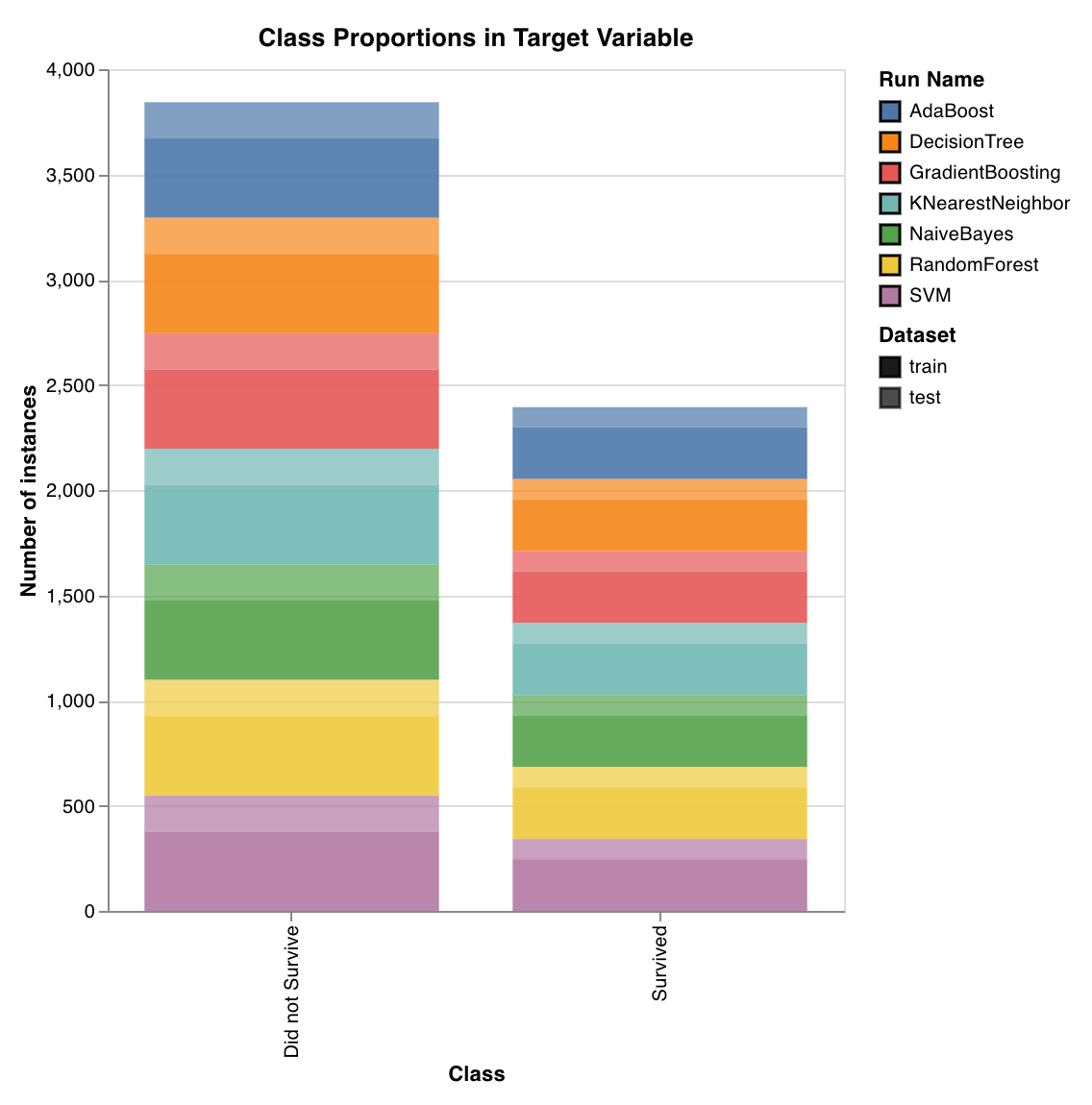 Trace la répartition des classes cibles dans les ensembles d'entraînement et de test. Utile pour détecter des classes déséquilibrées et s'assurer qu'une classe n'a pas une influence disproportionnée sur le modèle.
`wandb.sklearn.plot_class_proportions(y_train, y_test, ['dog', 'cat', 'owl'])`
* y\_train (arr): Étiquettes de l'ensemble d'entraînement.
* y\_test (arr): Étiquettes de l'ensemble de test.
* labels (list): Étiquettes nommées de la variable cible (y).
Trace la répartition des classes cibles dans les ensembles d'entraînement et de test. Utile pour détecter des classes déséquilibrées et s'assurer qu'une classe n'a pas une influence disproportionnée sur le modèle.
`wandb.sklearn.plot_class_proportions(y_train, y_test, ['dog', 'cat', 'owl'])`
* y\_train (arr): Étiquettes de l'ensemble d'entraînement.
* y\_test (arr): Étiquettes de l'ensemble de test.
* labels (list): Étiquettes nommées de la variable cible (y).
### Courbe précision-rappel
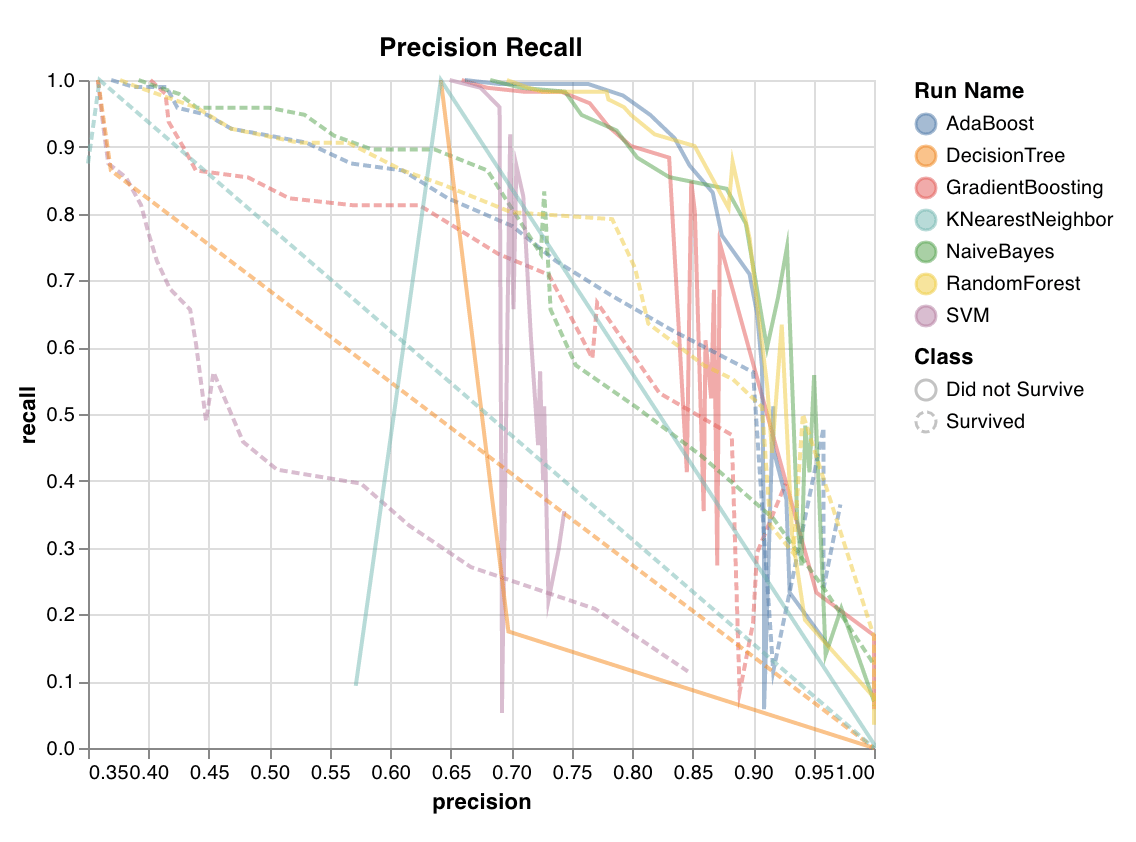 Calcule le compromis entre la précision et le rappel pour différents seuils. Une grande aire sous la courbe indique à la fois un rappel élevé et une précision élevée, où une précision élevée correspond à un faible taux de faux positifs, et un rappel élevé à un faible taux de faux négatifs.
Des scores élevés pour les deux montrent que le classifieur renvoie des résultats précis (précision élevée) et qu'il identifie la majorité des cas positifs (rappel élevé). La courbe PR est utile lorsque les classes sont très déséquilibrées.
`wandb.sklearn.plot_precision_recall(y_true, y_probas, labels)`
* y\_true (arr): Étiquettes de l'ensemble de test.
* y\_probas (arr): Probabilités prédites sur l'ensemble de test.
* labels (list): Noms des étiquettes pour la variable cible (y).
Calcule le compromis entre la précision et le rappel pour différents seuils. Une grande aire sous la courbe indique à la fois un rappel élevé et une précision élevée, où une précision élevée correspond à un faible taux de faux positifs, et un rappel élevé à un faible taux de faux négatifs.
Des scores élevés pour les deux montrent que le classifieur renvoie des résultats précis (précision élevée) et qu'il identifie la majorité des cas positifs (rappel élevé). La courbe PR est utile lorsque les classes sont très déséquilibrées.
`wandb.sklearn.plot_precision_recall(y_true, y_probas, labels)`
* y\_true (arr): Étiquettes de l'ensemble de test.
* y\_probas (arr): Probabilités prédites sur l'ensemble de test.
* labels (list): Noms des étiquettes pour la variable cible (y).
### Importance des fonctionnalités
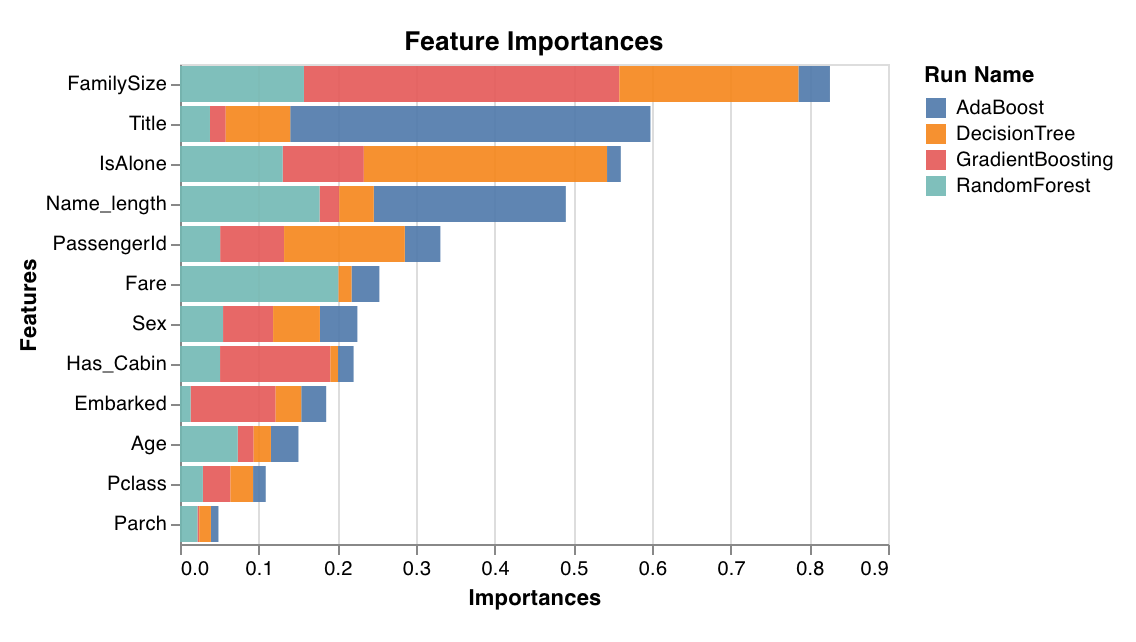 Évalue et trace l’importance de chaque fonctionnalité pour la tâche de classification. Fonctionne uniquement avec les classifieurs qui possèdent un attribut `feature_importances_`, comme les arbres.
`wandb.sklearn.plot_feature_importances(model, ['width', 'height, 'length'])`
* model (clf): Prend en entrée un classifieur ajusté.
* feature\_names (list): Noms des fonctionnalités. Rend les graphiques plus lisibles en remplaçant les indices des fonctionnalités par les noms correspondants.
Évalue et trace l’importance de chaque fonctionnalité pour la tâche de classification. Fonctionne uniquement avec les classifieurs qui possèdent un attribut `feature_importances_`, comme les arbres.
`wandb.sklearn.plot_feature_importances(model, ['width', 'height, 'length'])`
* model (clf): Prend en entrée un classifieur ajusté.
* feature\_names (list): Noms des fonctionnalités. Rend les graphiques plus lisibles en remplaçant les indices des fonctionnalités par les noms correspondants.
### Courbe de calibration
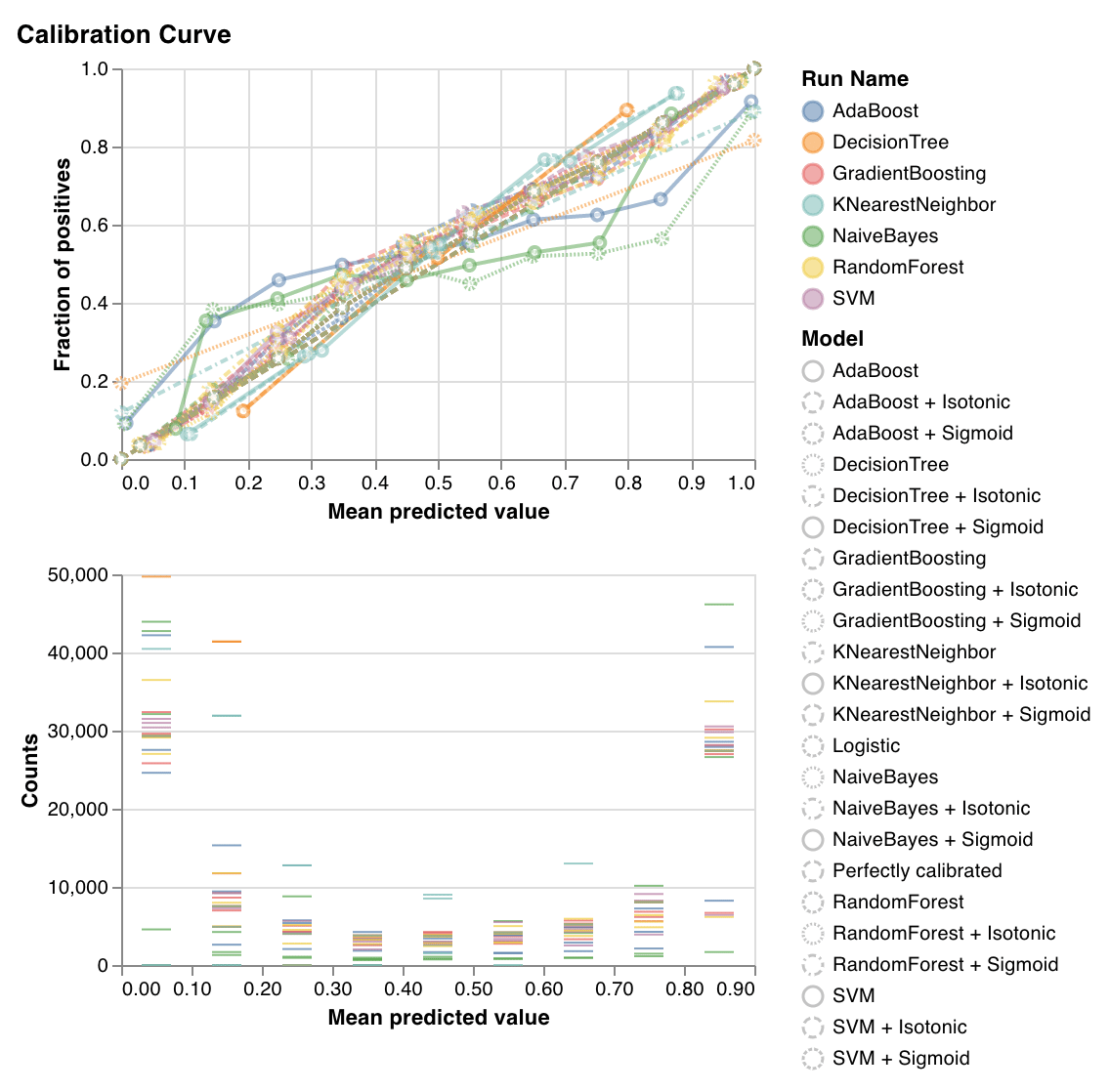 Montre dans quelle mesure les probabilités prédites d’un classifieur sont bien calibrées et comment calibrer un classifieur non calibré. Compare les probabilités prédites estimées par un modèle de régression logistique de référence, le modèle passé en argument, ainsi que ses calibrations isotone et sigmoïde.
Plus les courbes de calibration sont proches de la diagonale, mieux c’est. Une courbe en sigmoïde inversée représente un classifieur surajusté, tandis qu’une courbe en sigmoïde représente un classifieur sous-ajusté. En entraînant les calibrations isotone et sigmoïde du modèle et en comparant leurs courbes, nous pouvons déterminer si le modèle est en surajustement ou en sous-ajustement et, le cas échéant, quelle calibration (sigmoïde ou isotone) pourrait aider à corriger le problème.
Pour plus de détails, consultez [la documentation de sklearn](https://scikit-learn.org/stable/auto_examples/calibration/plot_calibration_curve.html).
`wandb.sklearn.plot_calibration_curve(clf, X, y, 'RandomForestClassifier')`
* model (clf) : Prend en entrée un classifieur ajusté.
* X (arr) : Fonctionnalités de l’ensemble d’entraînement.
* y (arr) : Étiquettes de l’ensemble d’entraînement.
* model\_name (str) : Nom du modèle. Valeur par défaut : 'Classifier'
Montre dans quelle mesure les probabilités prédites d’un classifieur sont bien calibrées et comment calibrer un classifieur non calibré. Compare les probabilités prédites estimées par un modèle de régression logistique de référence, le modèle passé en argument, ainsi que ses calibrations isotone et sigmoïde.
Plus les courbes de calibration sont proches de la diagonale, mieux c’est. Une courbe en sigmoïde inversée représente un classifieur surajusté, tandis qu’une courbe en sigmoïde représente un classifieur sous-ajusté. En entraînant les calibrations isotone et sigmoïde du modèle et en comparant leurs courbes, nous pouvons déterminer si le modèle est en surajustement ou en sous-ajustement et, le cas échéant, quelle calibration (sigmoïde ou isotone) pourrait aider à corriger le problème.
Pour plus de détails, consultez [la documentation de sklearn](https://scikit-learn.org/stable/auto_examples/calibration/plot_calibration_curve.html).
`wandb.sklearn.plot_calibration_curve(clf, X, y, 'RandomForestClassifier')`
* model (clf) : Prend en entrée un classifieur ajusté.
* X (arr) : Fonctionnalités de l’ensemble d’entraînement.
* y (arr) : Étiquettes de l’ensemble d’entraînement.
* model\_name (str) : Nom du modèle. Valeur par défaut : 'Classifier'
### Matrice de confusion
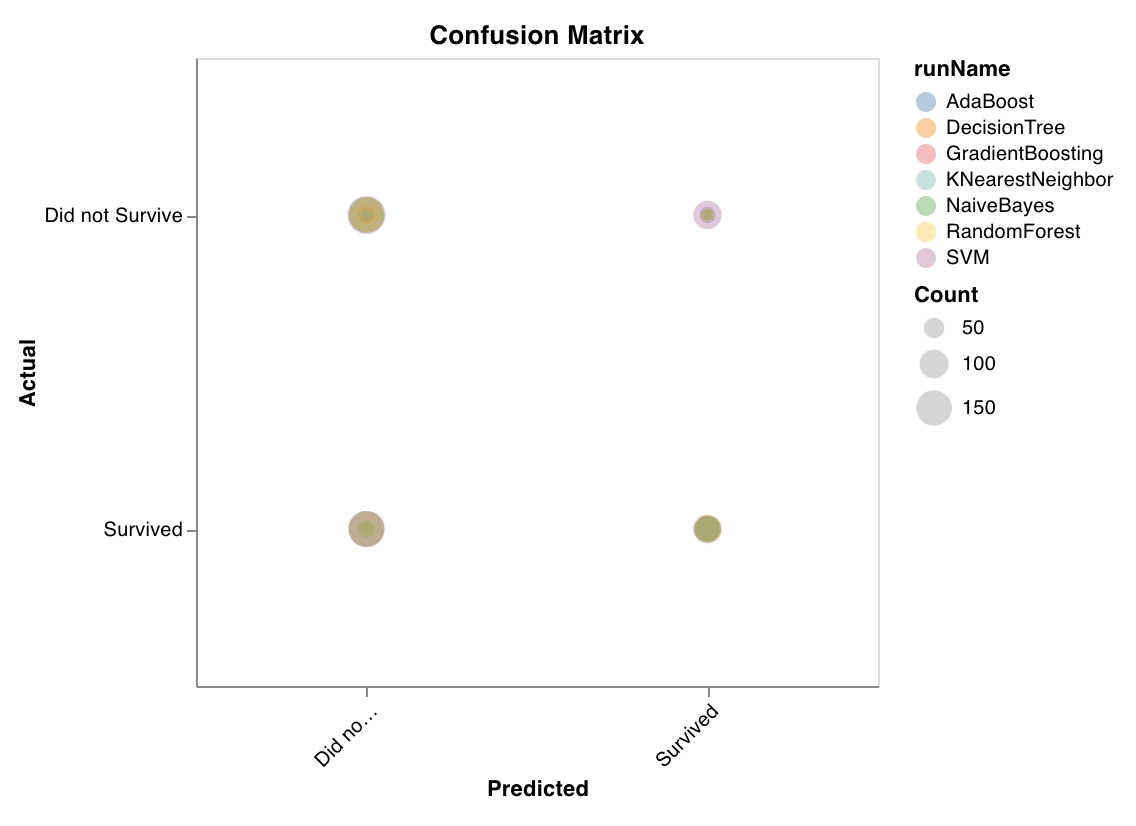 Calcule la matrice de confusion pour évaluer la précision d'une classification. Elle est utile pour évaluer la qualité des prédictions du modèle et repérer des tendances dans les prédictions pour lesquelles le modèle se trompe. La diagonale représente les prédictions que le modèle a correctement faites, c'est-à-dire lorsque l'étiquette réelle est égale à l'étiquette prédite.
`wandb.sklearn.plot_confusion_matrix(y_true, y_pred, labels)`
* y\_true (arr): Étiquettes de l'ensemble de test.
* y\_pred (arr): Étiquettes prédites de l'ensemble de test.
* labels (list): Étiquettes nommées de la variable cible (y).
Calcule la matrice de confusion pour évaluer la précision d'une classification. Elle est utile pour évaluer la qualité des prédictions du modèle et repérer des tendances dans les prédictions pour lesquelles le modèle se trompe. La diagonale représente les prédictions que le modèle a correctement faites, c'est-à-dire lorsque l'étiquette réelle est égale à l'étiquette prédite.
`wandb.sklearn.plot_confusion_matrix(y_true, y_pred, labels)`
* y\_true (arr): Étiquettes de l'ensemble de test.
* y\_pred (arr): Étiquettes prédites de l'ensemble de test.
* labels (list): Étiquettes nommées de la variable cible (y).
### Métriques de synthèse
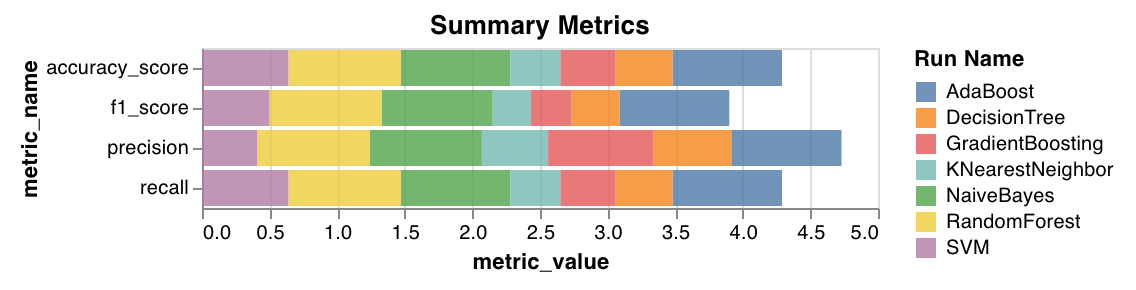 * Calcule des métriques de synthèse pour la classification, comme `mse`, `mae` et le score `r2`.
* Calcule des métriques de synthèse pour la régression, comme `f1`, accuracy, la précision et le rappel.
`wandb.sklearn.plot_summary_metrics(model, X_train, y_train, X_test, y_test)`
* model (clf or reg): Prend en entrée un régresseur ou un classifieur ajusté.
* X (arr): Fonctionnalités de l’ensemble d’entraînement.
* y (arr): Étiquettes de l’ensemble d’entraînement.
* X\_test (arr): Fonctionnalités de l’ensemble de test.
* y\_test (arr): Étiquettes de l’ensemble de test.
* Calcule des métriques de synthèse pour la classification, comme `mse`, `mae` et le score `r2`.
* Calcule des métriques de synthèse pour la régression, comme `f1`, accuracy, la précision et le rappel.
`wandb.sklearn.plot_summary_metrics(model, X_train, y_train, X_test, y_test)`
* model (clf or reg): Prend en entrée un régresseur ou un classifieur ajusté.
* X (arr): Fonctionnalités de l’ensemble d’entraînement.
* y (arr): Étiquettes de l’ensemble d’entraînement.
* X\_test (arr): Fonctionnalités de l’ensemble de test.
* y\_test (arr): Étiquettes de l’ensemble de test.
### Graphique en coude
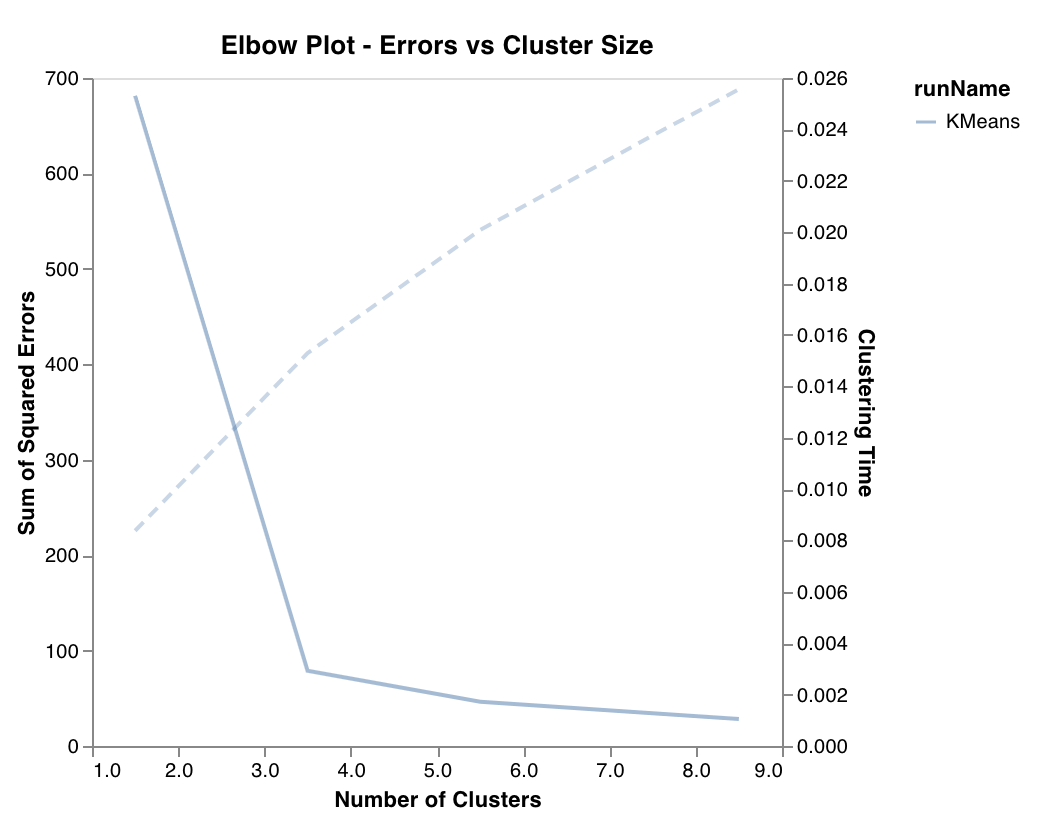 Mesure et représente le pourcentage de variance expliquée en fonction du nombre de clusters, ainsi que les temps d’entraînement. Utile pour choisir le nombre optimal de clusters.
`wandb.sklearn.plot_elbow_curve(model, X_train)`
* model (clusterer): Accepte un clusterer ajusté.
* X (arr): Fonctionnalités de l’ensemble d’entraînement.
Mesure et représente le pourcentage de variance expliquée en fonction du nombre de clusters, ainsi que les temps d’entraînement. Utile pour choisir le nombre optimal de clusters.
`wandb.sklearn.plot_elbow_curve(model, X_train)`
* model (clusterer): Accepte un clusterer ajusté.
* X (arr): Fonctionnalités de l’ensemble d’entraînement.
### Graphique de silhouette
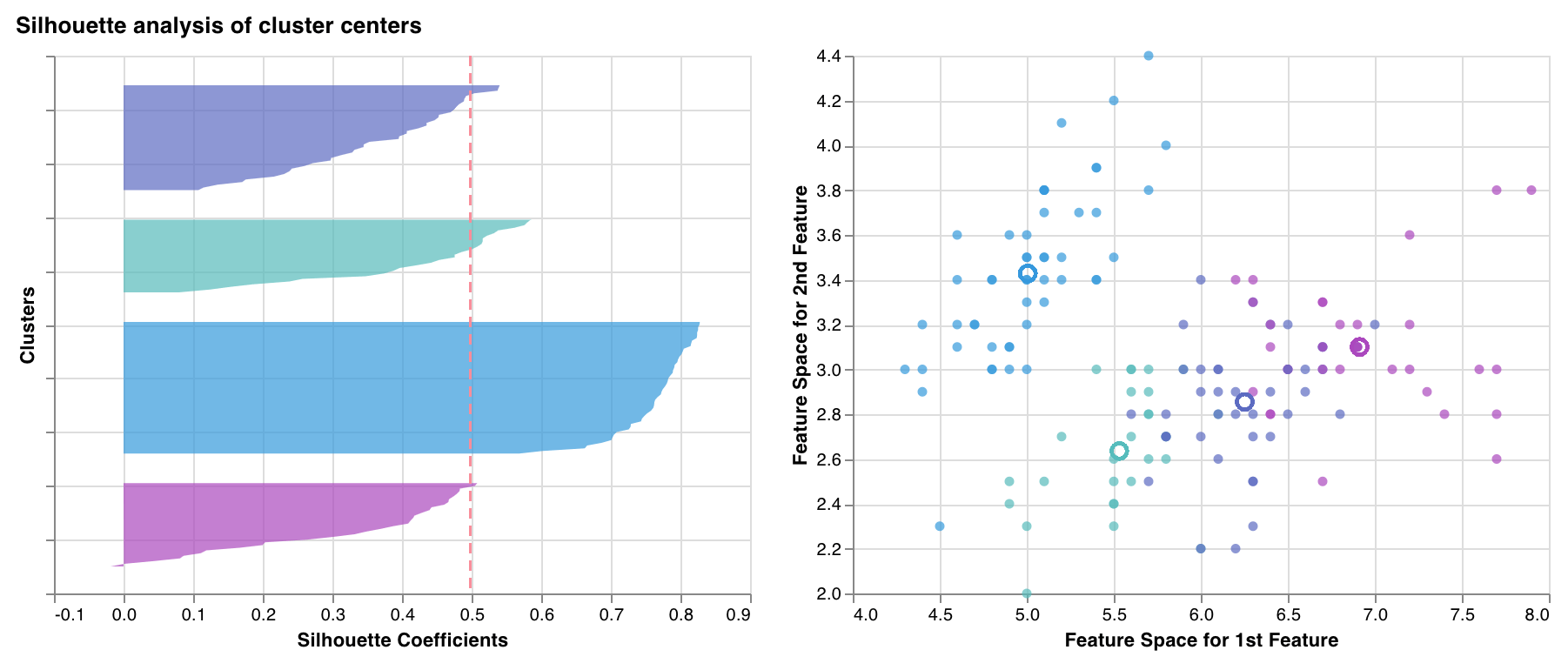 Mesure et représente graphiquement à quel point chaque point d’un cluster est proche des points des clusters voisins. L’épaisseur des clusters correspond à leur taille. La ligne verticale représente le score de silhouette moyen de tous les points.
Des coefficients de silhouette proches de +1 indiquent que l’échantillon est très éloigné des clusters voisins. Une valeur de 0 indique que l’échantillon se trouve sur, ou très près de, la frontière de décision entre deux clusters voisins, et des valeurs négatives indiquent que ces échantillons ont pu être assignés au mauvais cluster.
En général, on cherche à ce que tous les scores de silhouette des clusters soient supérieurs à la moyenne (au-delà de la ligne rouge) et aussi proches que possible de 1. On préfère également des tailles de cluster qui reflètent les structures sous-jacentes des données.
`wandb.sklearn.plot_silhouette(model, X_train, ['spam', 'not spam'])`
* model (clusterer) : Prend en entrée un algorithme de clustering ajusté.
* X (arr) : Fonctionnalités de l’ensemble d’entraînement.
* cluster\_labels (list) : Noms des étiquettes de cluster. Rend les graphiques plus faciles à lire en remplaçant les indices de cluster par les noms correspondants.
Mesure et représente graphiquement à quel point chaque point d’un cluster est proche des points des clusters voisins. L’épaisseur des clusters correspond à leur taille. La ligne verticale représente le score de silhouette moyen de tous les points.
Des coefficients de silhouette proches de +1 indiquent que l’échantillon est très éloigné des clusters voisins. Une valeur de 0 indique que l’échantillon se trouve sur, ou très près de, la frontière de décision entre deux clusters voisins, et des valeurs négatives indiquent que ces échantillons ont pu être assignés au mauvais cluster.
En général, on cherche à ce que tous les scores de silhouette des clusters soient supérieurs à la moyenne (au-delà de la ligne rouge) et aussi proches que possible de 1. On préfère également des tailles de cluster qui reflètent les structures sous-jacentes des données.
`wandb.sklearn.plot_silhouette(model, X_train, ['spam', 'not spam'])`
* model (clusterer) : Prend en entrée un algorithme de clustering ajusté.
* X (arr) : Fonctionnalités de l’ensemble d’entraînement.
* cluster\_labels (list) : Noms des étiquettes de cluster. Rend les graphiques plus faciles à lire en remplaçant les indices de cluster par les noms correspondants.
### Graphique des valeurs aberrantes potentielles
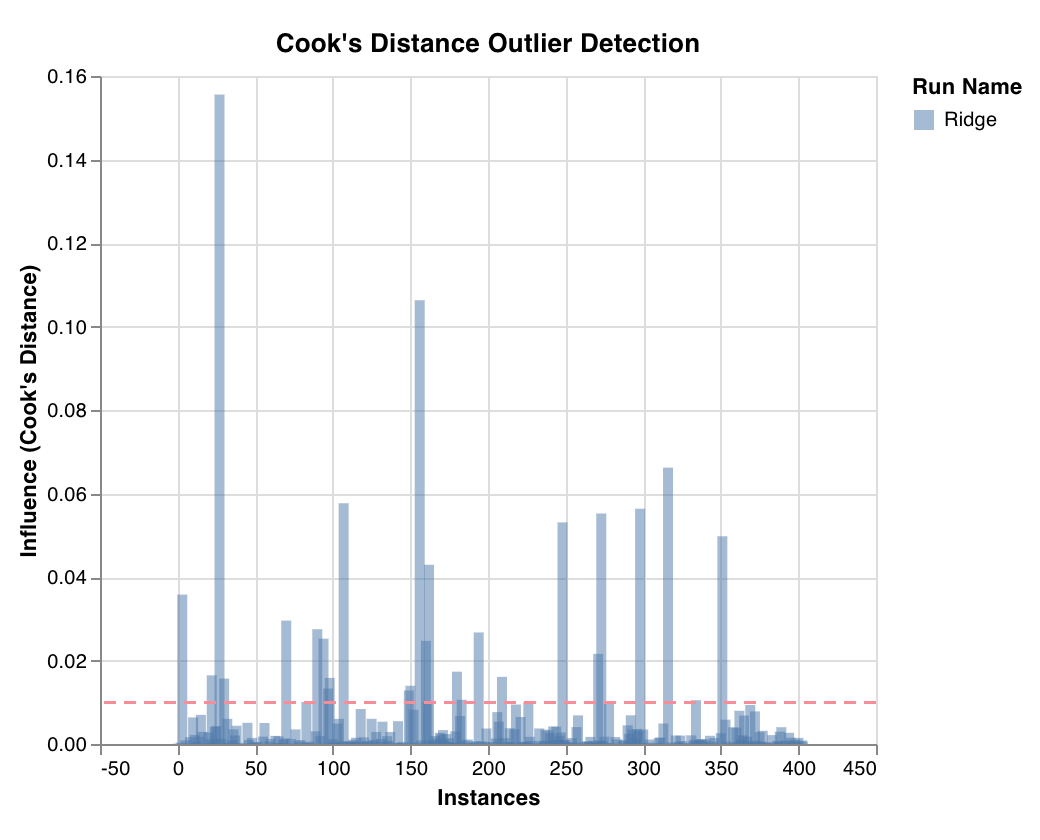 Mesure l'influence d'un point de données sur un modèle de régression à l'aide de la distance de Cook. Les instances dont l'influence est fortement disproportionnée peuvent être des valeurs aberrantes potentielles. Utile pour la détection des valeurs aberrantes.
`wandb.sklearn.plot_outlier_candidates(model, X, y)`
* model (regressor): Accepte un classificateur ajusté.
* X (arr): Fonctionnalités de l’ensemble d’entraînement.
* y (arr): Étiquettes de l’ensemble d’entraînement.
Mesure l'influence d'un point de données sur un modèle de régression à l'aide de la distance de Cook. Les instances dont l'influence est fortement disproportionnée peuvent être des valeurs aberrantes potentielles. Utile pour la détection des valeurs aberrantes.
`wandb.sklearn.plot_outlier_candidates(model, X, y)`
* model (regressor): Accepte un classificateur ajusté.
* X (arr): Fonctionnalités de l’ensemble d’entraînement.
* y (arr): Étiquettes de l’ensemble d’entraînement.
### Graphique des résidus
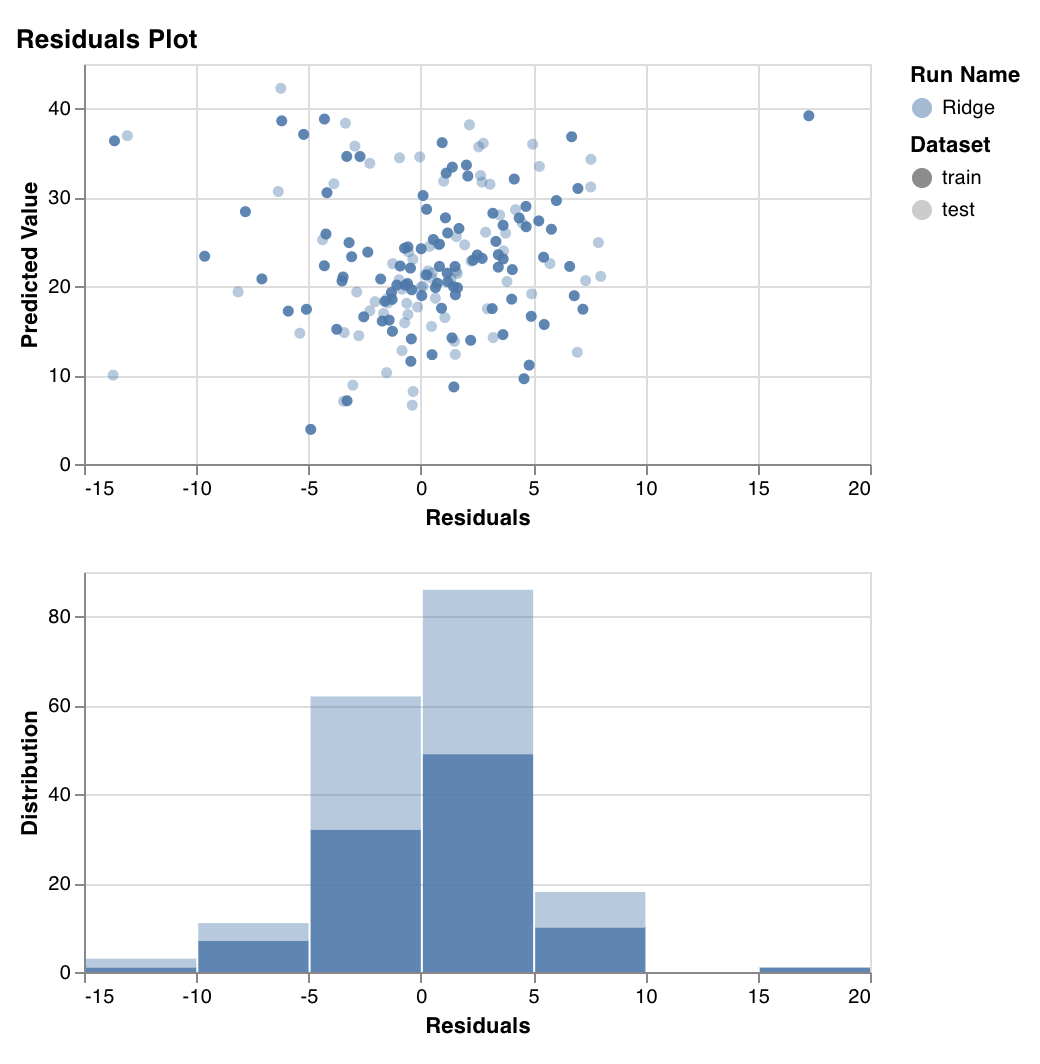 Mesure et représente les valeurs cibles prédites (axe des y) par rapport à l'écart entre les valeurs cibles réelles et prédites (axe des x), ainsi que la distribution de l'erreur résiduelle.
En général, les résidus d'un modèle bien ajusté devraient être répartis aléatoirement, car un bon modèle explique la plupart des phénomènes d'un jeu de données, à l'exception de l'erreur aléatoire.
`wandb.sklearn.plot_residuals(model, X, y)`
* model (regressor): Prend un régresseur ajusté.
* X (arr): Fonctionnalités de l'ensemble d'entraînement.
* y (arr): Étiquettes de l'ensemble d'entraînement.
Si vous avez des questions, nous serons ravis d'y répondre dans notre [communauté Slack](https://wandb.me/slack).
Mesure et représente les valeurs cibles prédites (axe des y) par rapport à l'écart entre les valeurs cibles réelles et prédites (axe des x), ainsi que la distribution de l'erreur résiduelle.
En général, les résidus d'un modèle bien ajusté devraient être répartis aléatoirement, car un bon modèle explique la plupart des phénomènes d'un jeu de données, à l'exception de l'erreur aléatoire.
`wandb.sklearn.plot_residuals(model, X, y)`
* model (regressor): Prend un régresseur ajusté.
* X (arr): Fonctionnalités de l'ensemble d'entraînement.
* y (arr): Étiquettes de l'ensemble d'entraînement.
Si vous avez des questions, nous serons ravis d'y répondre dans notre [communauté Slack](https://wandb.me/slack).
## Exemple
* [Exécuter sur Colab](https://wandb.me/scikit-colab) : un notebook simple pour bien démarrer.